
Sie sitzen in einem Café. Ein Lied erklingt aus den Lautsprechern – Sie wissen, dass Sie es kennen, aber der Name will Ihnen einfach nicht einfallen. Sie ziehen Ihr Smartphone heraus, tippen auf Shazam, und innerhalb von fünf Sekunden liefert Ihnen die App den genauen Titel, den Künstler und das Album. Kein Liedtext-Eintippen, kein Summen, kein Suchen. Nur rohes Audio, aufgenommen in einem lauten Raum.
Das fühlt sich wie Magie an. Ist es aber nicht. Hinter diesem Fingertipp verbirgt sich einer der elegantesten Algorithmen der angewandten Mathematik – ein System, das auf Signalverarbeitung, kombinatorischem Hashing und probabilistischem Matching basiert und selbst bei Hintergrundgeräuschen, minderwertigen Mikrofonen und verkürzten Aufnahmen zuverlässig funktioniert. So funktioniert es.
Eine kurze Geschichte: Von der Pub-Epiphanie bis zur Übernahme durch Apple
Die Geschichte beginnt im Jahr 1999, als Chris Barton – ein MBA-Student an der UC Berkeley – in einer Londoner Bar frustriert feststellte, dass er ein Lied, das über die Lautsprecher lief, nicht identifizieren konnte. Er hatte eine einfache, aber radikale Idee: Was wäre, wenn ein Telefon das für einen erledigen könnte, nur anhand des Schalls in der Luft?
Barton gründete Shazam Entertainment Ltd zusammen mit Philip Inghelbrecht und Dhiraj Mukherjee. Die entscheidende Einstellung erfolgte, als Professor Julius Smith von der Stanford University sie auf Avery Wang aufmerksam machte, einen Doktor der digitalen Signalverarbeitung. Wangs erstes Urteil über das Projekt war direkt: „Das ist unmöglich.“ Die Herausforderungen waren beträchtlich – das System musste Musik in Echtzeit erkennen, inmitten von Umgebungslärm, in einem Maßstab von Millionen von Songs und über die bekanntermaßen minderwertigen Audiokanäle früher Mobiltelefone.
Wang wollte fast kündigen. Doch im Juni 2000 knackte er das Problem und erfand das Fingerprinting-System, das Shazam bis heute antreibt.
Im Jahr 2002 startete der Dienst in Großbritannien – nicht als App, sondern als vierstellige Telefonnummer (2580). Benutzer riefen die Nummer an, hielten ihr Telefon an einen Lautsprecher und erhielten eine Textnachricht mit dem Namen des Liedes. Die Wahl von 2580 war beabsichtigt: Diese Tasten sind in einer geraden vertikalen Linie in der Mitte eines alten Handy-Tastenfeldes angeordnet, was es unglaublich einfach machte, die Nummer unterwegs in einem lauten Pub zu wählen. Die Datenbank enthielt beim Start eine Million Songs und antwortete in etwa 15 Sekunden.
Als Apple 2008 den App Store startete, änderte sich über Nacht alles. Shazam war eine der ersten verfügbaren Apps, und die Reibungsverluste verschwanden komplett. Bis 2022 wurde die App über 2 Milliarden Mal heruntergeladen. Apple gab im Dezember 2017 offiziell seine Absicht bekannt, Shazam zu erwerben, und schloss den Deal im September 2018 für geschätzte 400 Millionen US-Dollar offiziell ab.
Der von Avery Wang in seinem wegweisenden Paper aus dem Jahr 2003 – „An Industrial-Strength Audio Search Algorithm“ – veröffentlichte Algorithmus bleibt bis heute die grundlegende Architektur des Systems.
Das Kernproblem: Warum Audioerkennung so schwierig ist
Bevor wir die Lösung untersuchen, ist es wichtig zu verstehen, warum die Erkennung eines Songs anhand eines verrauschten 10-Sekunden-Samples ein schwieriges rechnerisches Problem darstellt.
Die Herausforderung ist dreifach:
- Skalierung. Shazams Datenbank enthält Hunderte Millionen von Songs. Ein Fingerabdruck aus einem Sample muss innerhalb von Sekunden mit diesem gesamten Katalog abgeglichen werden.
- Rauschen. Das erfasste Audio enthält Hintergrundgeräusche, Raumakustik, qualitativ minderwertige Mikrofonkompression und Übertragungsartefakte – nichts davon ist in der makellosen Studioaufnahme in der Datenbank vorhanden.
- Zeitlicher Versatz. Das Sample könnte an jeder beliebigen Stelle des Songs aufgenommen worden sein – der Anfang, die Bridge, das Outro –, daher darf der Abgleich nicht von der absoluten Position innerhalb des Titels abhängen.
Ein naiver Ansatz – der Vergleich roher Wellenformen – würde bei allen drei Tests sofort scheitern. Die Wellenform deiner aufgenommenen Probe und die Wellenform des Studiotitels sind schlicht zu unterschiedlich, um direkt korreliert zu werden. Es ist eine intelligentere Darstellung des Audios erforderlich.
Schritt 1: Erfassung und Optimierung des Signals
Wenn Sie auf Shazam tippen, zeichnet die App ein 5 bis 10 Sekunden langes Audio-Sample über das Mikrofon Ihres Geräts auf. Dieser analoge Schall – eine kontinuierliche Druckwelle, die sich durch die Luft ausbreitet – wird durch einen Prozess namens Analog-Digital-Wandlung (ADC) in ein digitales Signal umgewandelt.
Während Standard-High-Fidelity-Audio typischerweise mit 44.100 Samples pro Sekunde (44,1 kHz) aufgenommen wird, nutzt Shazam eine ausgeklügelte Downsampling- und Optimierungsstrategie, um Speicher und Rechenleistung zu sparen. Das eingehende Audiosignal wird auf 8 kHz (oder manchmal 11 kHz) heruntergerechnet und von Stereo in einen einzelnen Mono-Kanal umgewandelt, bevor jegliche weitere mathematische Verarbeitung stattfindet.
Warum funktioniert diese Optimierung so gut? Das menschliche Gehör reicht bis zu 20 kHz, aber die überwiegende Mehrheit der einzigartigen „energetischen“ Merkmale, die populäre Musik auszeichnen – wie Gesang, perkussive Transienten und dominante harmonische Strukturen – liegt bequem unter 4 kHz. Gemäß dem Nyquist-Shannon-Abtasttheorem ist eine Abtastrate von 8 kHz mathematisch ausreichend, um alle Frequenzen bis zu 4 kHz perfekt zu erfassen und zu rekonstruieren. Dieser Optimierungsschritt komprimiert das Datenvolumen, das der Algorithmus jede Sekunde verarbeiten muss, drastisch, ohne die für die Identifizierung wesentlichen Merkmale zu verlieren.
Schritt 2: Die Fourier-Transformation — Zerlegung von Klang in Frequenzen
Das grundlegende mathematische Werkzeug, das Shazam erst möglich macht, ist die Diskrete Fourier-Transformation (DFT), die in der Praxis mittels der rechenoptimierten Fast Fourier Transform (FFT) implementiert wird.
Die DFT nimmt ein Signal im Zeitbereich – eine Abfolge von Amplituden – und zerlegt es in seine konstituierenden Frequenzkomponenten. Einfach ausgedrückt: Sie sagt einem nicht, wie laut der Ton zu einem bestimmten Zeitpunkt ist, sondern welche Frequenzen vorhanden sind und mit welcher Intensität.
Mathematisch gesehen wird die DFT eines Signals der Länge elegant wie folgt ausgedrückt:
Dabei gilt:
- ist das Eingangssignal im Zeitbereich (Amplitude zum Abtastpunkt )
- ist der komplexe Ausgang im Frequenzbereich beim Frequenz-Bin
- ist eine komplexe Exponentialfunktion, die einen rotierenden Einheitsvektor darstellt
- liefert den Betrag (Amplitude) bei der Frequenz
Die FFT berechnet diese Transformation in Zeit anstelle der naiven , was eine Echtzeit-Audioverarbeitung auf handelsüblicher Hardware hochgradig praktikabel macht.
Das Problem bei einer einzigen FFT über das gesamte Sample besteht darin, dass Musik nicht stationär ist – Frequenzen ändern sich dynamisch über die Zeit. Eine einzelne FFT würde Ihnen zwar sagen, dass eine Gitarre, ein Klavier und ein Bass irgendwo vorhanden sind, aber sie würde den zeitlichen Kontext – wann jede Note auftritt – vollständig verlieren.
Schritt 3: Die Kurzzeit-Fourier-Transformation und das Spektrogramm
Um zu erfassen, wie sich Frequenzen im Zeitverlauf entwickeln, wendet Shazam die Kurzzeit-Fourier-Transformation (STFT) an. Anstatt eine einzige massive FFT über den gesamten Clip laufen zu lassen, schiebt der Algorithmus ein kleines Analysefenster – typischerweise 10–30 Millisekunden breit – entlang des Signals und berechnet in jedem diskreten Intervall eine FFT.
Das Ergebnis ist eine 2D-Darstellung:
- Horizontale Achse: Zeit (jede Fensterposition)
- Vertikale Achse: Frequenz (jeder FFT-Frequenz-Bin)
- Farbe/Intensität: Amplitude (Stärke der jeweiligen Frequenz zu diesem Zeitpunkt)
Diese 2D-Struktur wird Spektrogramm genannt und dient als Kernlandschaft für das Fingerprinting.
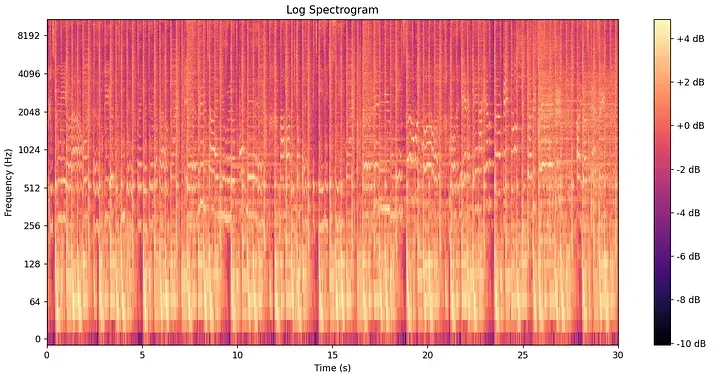
Um ein Artefakt namens spektrale Leckage (Spectral Leakage) zu verhindern – bei der Energie von einem scharfen Frequenz-Bin aufgrund der abrupten Abschneidungen eines rechteckigen Fensters in benachbarte Bins „ausblutet“ –, wendet die STFT eine Hamming-Fensterfunktion an. Diese glatte Glockenkurve verjüngt die Kanten jedes Analyse-Frames. Das Hamming-Fenster ist mathematisch wie folgt definiert:
Ein Spektrogramm eines Songs erfasst sein vollständiges akustisches Fingerabdruck-Gitter. Der Vergleich roher Matrizen über eine Datenbank von Millionen von Songs wäre jedoch rechnerisch extrem aufwendig. Es bedarf einer weiteren Abstraktion.
Schritt 4: Die Konstellationskarte — Extrahierung spektraler Spitzen
Hier zeigt sich die zentrale Erkenntnis von Avery Wang. Der Großteil eines Spektrogramms besteht aus Hintergrundrauschen, Hall und energiearmen Füllsignalen. Die akustisch bedeutsamen Elemente in der Musik – der transiente Schlag einer Kick-Drum, der Einsatz eines Gitarrenakkords oder der Höhepunkt einer Gesangsmelodie – manifestieren sich als lokale Maxima im Spektrogramm. Dies sind Punkte, die intensiver sind als alle ihre unmittelbaren Nachbarn in Zeit und Frequenz.
Der Algorithmus von Shazam identifiziert diese spektralen Spitzen (Spectral Peaks) und verwirft alles andere. Eine Spitze ist ein Punkt , dessen Betrag alle Nachbarn innerhalb eines definierten lokalen Bereichs auf dem 2D-Zeit-Frequenz-Gitter übersteigt.
Dieser Vorgang reduziert das dichte Spektrogramm auf ein dünn besetztes Streudiagramm von Koordinatenpaaren. Da dieses Streudiagramm an Sterne am Nachthimmel erinnert, wird es formal als Konstellationskarte bezeichnet.
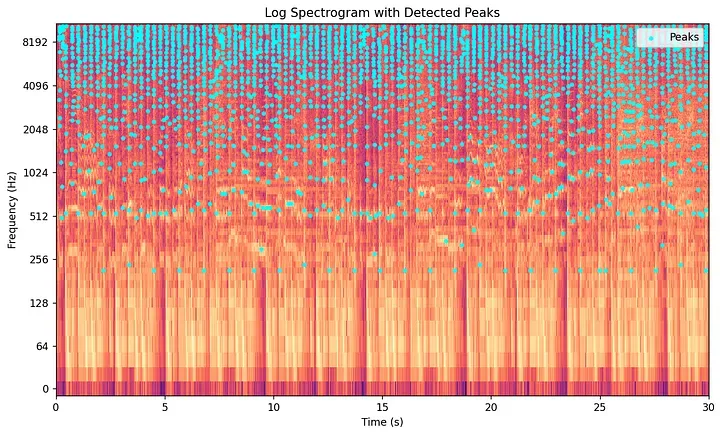
Dieser Schritt bietet eine starke Widerstandsfähigkeit gegen Rauschen. Hintergrundgeplapper oder Verzerrungen durch minderwertige Lautsprecher verteilen die Energie gleichmäßig und auf niedrigem Niveau über das Spektrogrammgitter. Sie erzeugen nur selten die dominanten, konzentrierten lokalen Spitzen, die erforderlich sind, um den Schwellenwert-Schritt zu bestehen. Die spektralen Spitzen, die übrig bleiben, sind die akustisch stärksten Elemente, was es Shazam ermöglicht, selbst in einer chaotischen Bar zu funktionieren. Darüber hinaus komprimiert das Speichern nur der Spitzenkoordinaten anstelle vollständiger Spektrogramm-Matrizen die erforderliche Speicherkapazität um mehrere Größenordnungen.
Schritt 5: Kombinatorisches Hashing — Punkte in Fingerabdrücke verwandeln
Ein einzelner isolierter Punkt auf einer Konstellationskarte enthält nur sehr wenig Entropie. Eine Frequenz von 1.400 Hz kommt in Tausenden von verschiedenen Titeln vor. Was eine Audio-Signatur hochgradig unterscheidbar macht, ist ihre kombinatorische Beziehung zu umliegenden Punkten.
Um diese Spezifität freizuschalten, paart der Algorithmus von Shazam jeden Ankerpunkt mit mehreren Zielpunkten, die in eine vordefinierte Zeit-Frequenz-„Zielzone“ vor ihm fallen. Für jedes eindeutige Anker-Ziel-Paar berechnet er einen kompakten, hochgradig diskriminativen Hash aus drei strukturellen Variablen:
hash = (f_anchor, f_target, Δt)Dabei gilt:
f_anchorist die Frequenz des Anker-Peaksf_targetist die Frequenz des Ziel-PeaksΔt = t_target − t_anchorist die präzise Zeitdifferenz zwischen ihnen
Um die Datenbankleistung auf Prozessorebene zu maximieren, nutzte Wang eine elegante Bit-Packing-Strategie, um dieses gesamte Tripel in eine einzige 32-Bit vorzeichenlose Ganzzahl (uint32) zu kodieren:
- Frequenz des Ankers (): 9 Bits (Bereitstellung von 512 verschiedenen Frequenz-Bins)
- Frequenz des Ziels (): 9 Bits (Bereitstellung von 512 verschiedenen Frequenz-Bins)
- Zeitdifferenz (): 14 Bits
- Gesamt: Bits
Diese 32-Bit-Ganzzahlstruktur ermöglicht es der Datenbank des Systems, blitzschnelle Gleichheitsprüfungen auf Hardware-Ebene durchzuführen. Diese Hashes werden in einer massiven Hash-Tabelle gespeichert, die nach dem Hash-Wert selbst indiziert ist. Jeder Eintrag verweist direkt auf die entsprechende Titel-Identifikation und den absoluten Zeitstempel, an dem der Ankerpunkt in der Studioversion auftrat:
hash → { track_id, t_anchor }Da der Hash nur die relative Zeitdifferenz () zwischen den beiden Peaks erfasst und keine absolute Platzierung auf der Zeitachse, ist der resultierende Fingerabdruck vollständig translationsinvariant. Ein Sample, das von der Bridge eines Titels aufgenommen wurde, erzeugt identische Hashes wie diejenigen, die von diesem exakten Segment in der Datenbank-Masteraufnahme indiziert wurden.
Schritt 6: Probabilistisches Matching und Zeit-Offset-Abgleich
Wenn ein Benutzer Shazam auslöst, erstellt die App eine Live-Konstellationskarte und extrahiert mithilfe genau derselben Pipeline einen Satz von Abfrage-Hashes. Anschließend durchsucht sie die zentrale Datenbank nach Übereinstimmungen.
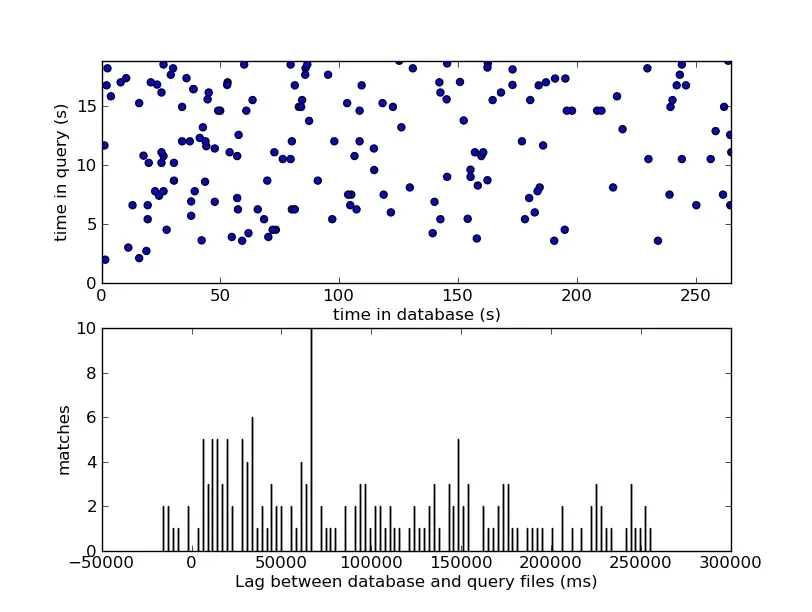
Da einzelne 32-Bit-Hashes in einer riesigen Datenbank kollidieren können, beweist ein einzelner Treffer nichts. Das Geheimrezept der Matching-Engine liegt in der kohärenten Zeit-Offset-Ausrichtung.
Für jeden gefundenen übereinstimmenden Hash zwischen dem Abfrage-Sample und einem Kandidaten-Track aus der Datenbank berechnet die Engine den zeitlichen Offset (Versatz) zwischen dem Auftreten des Hashes im Sample des Benutzers und seinem Auftreten im Studio-Track:
Wenn das abgefragte Sample tatsächlich zu einem bestimmten Kandidaten-Titel gehört, muss jeder einzelne überlebende Hash-Treffer aus diesem Sample denselben Offset-Wert ergeben, da alle ihre relativen Abstände zur Originalaufnahme beibehalten. Im Gegensatz dazu erzeugen zufällige Kollisionen aus falschen Titeln unkorrelierte, chaotische Offsets, die gleichmäßig über die Zeitachse verstreut sind.
Das System erstellt für jede Kandidaten-Titel-ID ein Histogramm dieser berechneten Offsets und sucht nach einer scharfen, unbestreitbaren Spitze (Peak) im Histogramm.
Das Finden einer Spitze im Histogramm ist eine diskrete Annäherung an die Identifizierung einer diagonalen Linie in einem 2D-Diagramm, bei dem eine Achse die Datenbankzeit () und die andere die Abfragezeit () darstellt. Wenn die übereinstimmenden Punkte perfekt entlang einer 45-Grad-Diagonalen (einer Steigung von ) ausgerichtet sind, bestätigt dies, dass beide Audioquellen mit exakt derselben Geschwindigkeit ablaufen. Eine signifikante Ansammlung von Punkten, die sich auf einen festen, konstanten Offset einigen (), liefert ein statistisch überwältigendes Signal, das Hintergrundgeräusche vollständig ausblendet.
Die Wahrscheinlichkeit hinter der Magie
Lassen wir die Lärmresistenz mathematisch explizit werden. Nehmen wir an, ein gegebener spektraler Peak hat eine Wahrscheinlichkeit , eine verrauschte Aufnahmeumgebung zu überstehen. Damit ein kombinatorischer Hash erfolgreich generiert werden kann, müssen sowohl sein Anker- als auch sein Ziel-Peak überleben. Die gemeinsame Wahrscheinlichkeit, dass ein einzelner Hash überlebt, beträgt:
Während zwar ein Opfer bei der rohen Überlebensrate für einzelne Hashes darstellt, zahlt sich dieser Kompromiss bei der Suche exponentiell aus. Ein einzelner überlebender, gepaarter Hash-Treffer mit korrekter Zeit-Ausrichtung ist weitaus spezifischer als ein isolierter Peak. Der Algorithmus ist strukturell so ausgelegt, dass er nur einen kleinen Bruchteil der gesamten Hashes eines Songs benötigt, um eine zweifelsfreie Übereinstimmung festzustellen, was es ermöglicht, beeinträchtigte Audioaufnahmen nahtlos wiederherzustellen.
Technisches Glossar
| Begriff | Definition |
|---|---|
| ADC | Analog-Digital-Wandlung — transformiert eine kontinuierliche Schallwelle in diskrete digitale Abtastwerte |
| Nyquist-Theorem | Besagt, dass ein Signal mit der doppelten seiner höchsten Frequenz abgetastet werden muss, um originalgetreu rekonstruiert zu werden |
| FFT | Fast Fourier Transform — ein -Algorithmus zur Zerlegung eines Signals in Frequenzkomponenten |
| STFT | Short-Time Fourier Transform — wendet FFT über gleitende Fenster an, um zeitlich variierenden Frequenzgehalt zu erfassen |
| Spektrogramm | Eine 2D-Zeit-Frequenz-Amplituden-Darstellung eines Audiosignals |
| Hamming-Fenster | Eine glatte Verjüngungsfunktion, die auf jeden STFT-Frame angewendet wird, um spektrales Leck (Spectral Leakage) zu reduzieren |
| Spektrale Spitze | Ein lokales Maximum im Spektrogramm — ein Punkt, dessen Amplitude alle Nachbarn in einer definierten Region übersteigt |
| Konstellationskarte | Ein spärlicher Satz von Koordinaten spektraler Spitzen, der die Basis für die Fingerabdruck-Generierung bildet |
| Kombinatorischer Hash | Ein 32-Bit-Hash, der kodiert — die zentrale Fingerabdruck-Einheit |
| Zeit-Offset-Abgleich | Die Matching-Technik, die Hash-Match-Offsets gruppiert, um eine kohärente Song-Identifikation zu bestätigen |
| Translationsinvarianz | Die Eigenschaft, dass der Fingerabdruck unabhängig davon ist, an welcher Stelle im Song das Sample beginnt |
„Kein maschinelles Lernen“ — Eine Richtigstellung für 2026
Der klassische Algorithmus von Avery Wang ist ein Meisterwerk reiner, deterministischer 1D/2D-Signalverarbeitung und schnellem Hashing. Er enthält keine neuronalen Netze, keine Gewichtungen und keine Modelle für maschinelles Lernen.
Wenn man die Architektur jedoch aus der Perspektive des Jahres 2026 betrachtet, ist eine kleine moderne Fußnote angebracht. Während das Kern-Framework für das Matching und die Fingerabdruck-Indizierung fest auf diesen mathematischen Prinzipien verankert bleibt, hat sich das moderne Shazam (innerhalb des Apple-Ökosystems) zu einem Hybridsystem entwickelt. Leichtgewichtige, hochoptimierte Deep-Learning-Modelle – insbesondere Convolutional Neural Networks (CNNs) – werden heute häufig in der initialen Ingestionsphase eingesetzt. Diese neuronalen Modelle dienen als ultraeffiziente Frontend-Filter, um extreme Hintergrundgeräusche in Cafés zu eliminieren, den Gesang zu isolieren oder eine Quellentrennung durchzuführen, bevor das Audio in die Phase der Konstellationskartierung eintritt.
Selbst mit den modernen KI-Erweiterungen beruhen die Kernarbeit, die Matching-Geschwindigkeit und die ultimative Zuverlässigkeit des Systems nach wie vor vollständig auf den wunderbaren mathematischen Grundlagen, die vor mehr als zwei Jahrzehnten gelegt wurden. Wenn Sie das nächste Mal auf diesen Button tippen, erleben Sie, wie die Fourier-Transformation etwas wahrhaft Zeitloses vollbringt.
