
你坐在一家咖啡馆里。扬声器里飘出一首歌——你知道自己听过,但名字却怎么也想不起来。你拿出手机,点击 Shazam,不到五秒钟,它就告诉了你准确的歌名、艺术家和专辑。无需输入歌词,无需哼唱,无需搜索。仅仅通过一个嘈杂的房间捕捉原始音频。
这感觉就像魔法。但事实并非如此。在这轻轻一按的背后,蕴含着应用数学中最优雅的算法之一——这是一个由信号处理、组合哈希和概率匹配构建的系统,即使在有背景噪音、麦克风质量差和录音不完整的情况下也能可靠地工作。以下是它的工作原理。
简史:从酒吧的灵感到苹果的收购
故事始于 1999 年,当时伦敦一家酒吧里,Chris Barton(当时是 UC Berkeley 的一名 MBA 学生)感到很沮丧,因为他无法识别扬声器里播放的一首歌。他提出了一个简单但激进的想法:如果手机能仅凭空气中的声音就为你做到这一点呢?
Barton 与 Philip Inghelbrecht 和 Dhiraj Mukherjee 共同创立了 Shazam Entertainment Ltd。最关键的聘用发生在斯坦福大学的 Professor Julius Smith 将他们引荐给数字信号处理博士 Avery Wang 时。Wang 对这个项目的最初结论很直接:“这不可能。” 挑战是巨大的——系统需要通过环境噪音,在数百万首歌曲的规模上,在早期手机臭名昭著的低质量音频通道上实时识别音乐。
Wang 差一点就放弃了。然后,在 2000 年 6 月,他攻克了这一难题,发明了沿用至今的 Shazam 音频指纹识别系统。
在 2002 年,该服务在英国推出——当时它不是一个应用程序,而是一个四位数的电话号码(2580)。用户会拨打这个号码,把手机对着扬声器,然后收到一条识别歌曲的文本短信。选择 2580 是有意的:这些按键在旧手机键盘的正中间排成一条垂直直线,使得在嘈杂的酒吧中移动时非常容易拨打。发布时的数据库包含 100 万首歌曲,需要大约 15 秒才能做出响应。
当苹果在 2008 年推出 App Store 时,一切在一夜之间发生了改变。Shazam 成为首批可用的应用程序之一,使用门槛彻底消失。到 2022 年,该应用的下载量已超过 20 亿次。苹果于 2017 年 12 月正式宣布同意收购 Shazam,并于 2018 年 9 月正式完成了这笔交易,耗资估计达 4 亿美元。
Avery Wang 在他 2003 年的里程碑式论文——“An Industrial-Strength Audio Search Algorithm” 中发表的算法,至今仍是该系统的基石架构。
核心问题:为什么音频识别这么难
在研究解决方案之前,有必要准确了解为什么从一段嘈杂的 10 秒样本中识别出一首歌是一个困难的计算问题。
挑战是三方面的:
- 规模。 Shazam 的数据库包含数亿首歌曲。来自样本的指纹必须在几秒钟内与整个目录进行匹配。
- 噪声。 捕获的音频包含背景闲聊、房间声学、低质量麦克风压缩和传输伪影——这些都不会出现在数据库中原始的录音室录音中。
- 时间偏移。 样本可以取自歌曲的任何时间点——片头、桥段、片尾——因此匹配不能依赖于曲目中的绝对位置。
一种天真的方法——对比原始波形(Waveforms)——会瞬间在所有这三项测试中失败。你录制的样本波形和录音室曲目的波形差异太大,无法直接进行相关性分析。我们需要一种更聪明的方式来表示音频。
步骤 1:捕捉并优化信号
当你点击 Shazam 时,该应用会通过你设备的麦克风录制一段 5-10 秒的音频样本。这种模拟声音——在空气中传播的连续压力波——通过一个名为**模数转换(ADC)**的过程转化为数字信号。
虽然标准的标准高保真音频通常以每秒 44,100 个样本 (44.1 kHz) 进行录制,但 Shazam 采用了巧妙的降采样和优化策略,以节省内存和处理能力。输入的音频在进行任何进一步的数学处理之前,会被降采样到 8 kHz(有时是 11 kHz),并从双声道转换为单一的单声道。
为什么这种优化效果这么好?人类的听觉上限可达 20 kHz,但区分流行音乐的绝大多数独特“能量”特征——如人声、打击乐瞬态和主导谐波结构——都舒适地处于 4 kHz 以下。根据 奈奎斯特-香农采样定理 (Nyquist-Shannon sampling theorem),8 kHz 的采样率在数学上足以完美捕捉和重构所有高达 4 kHz 的频率。这个优化步骤极大地压缩了算法每秒必须处理的数据量,同时又没有丢失识别所需的关键特征。
步骤 2:傅里叶变换——将声音分解为频率
使 Shazam 成为可能的底层数学工具是**离散傅里叶变换 (DFT),在实际应用中通过计算优化的快速傅里叶变换 (FFT)**来实现。
DFT 接收时域信号(一串振幅序列)并将其分解为组成它的频率成分。通俗地说:它告诉你的不是声音在某一时刻有多响,而是存在哪些频率,以及它们的强度如何。
在数学上,长度为 的信号 的 DFT 可以优雅地用 LaTeX 格式表示为:
其中:
- 是输入的时域信号(样本 处的振幅)
- 是在频率谱单元(Frequency bin) 处的复数频域输出
- 是表示旋转单位向量的复指数
- 给出了频率 处的幅值(振幅)
FFT 以 的时间复杂度计算此变换,而不是天真的 ,这使得在消费级硬件上进行实时音频处理变得高度可行。
对整个样本进行单一 FFT 的问题在于,音乐是非平稳的——频率随时间动态变化。单个 FFT 只能告诉你吉他、钢琴和贝斯都在某个地方存在,但完全丢失了每个音符何时发生的时域上下文。
步骤 3:短时傅里叶变换与声学谱图
为了捕捉频率随时间演变的过程,Shazam 应用了**短时傅里叶变换 (STFT)。算法没有在整段音频上运行一次巨大的 FFT,而是将一个通常为 10-30 毫秒宽的小分析窗(Window)**沿着信号滑动,并在每个离散的时间间隔内计算一个 FFT。
其结果是一个二维(2D)表示:
- 横轴: 时间(每个窗口的位置)
- 纵轴: 频率(每个 FFT 频率谱单元)
- 颜色/强度: 振幅(该频率在那个时刻的幅值)
这种二维结构被称为**声学谱图 (Spectrogram)**,它作为构建音频指纹的核心景观。
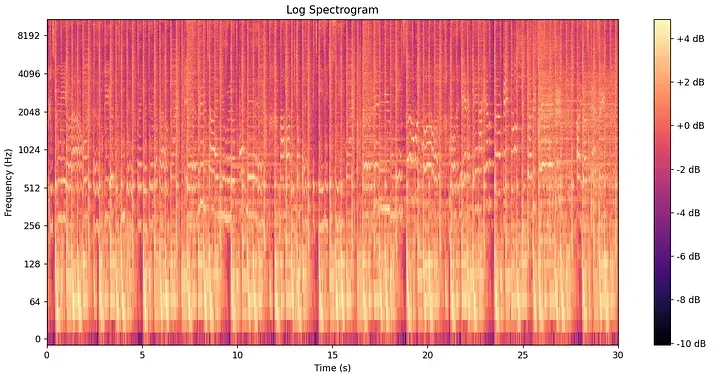
为了防止一种被称为**频谱泄漏 (Spectral leakage)的伪影——即由于矩形窗的急剧截断,来自一个尖锐频率谱单元的能量“渗漏”到相邻的谱单元中——STFT 应用了汉明窗 (Hamming window)**函数。这种平滑的钟形曲线淡化了每个分析帧的边缘。汉明窗 在数学上定义为:
一首歌的声学谱图捕捉了它完整的声学指纹网格。然而,在包含数百万首歌曲的数据库中对比原始矩阵在计算上仍然是瘫痪性的。我们需要进一步的抽象。
步骤 4:星座图——提取光谱峰值
这就是 Avery Wang 的核心洞察闪耀之处。声学谱图的大部分内容由背景噪音、混响和低能量填充物组成。音乐中具有声学意义的元素——大鼓的瞬态冲击、吉他弦鸣的开始或人声音调的巅峰——在声学谱图中表现为局部极大值(Local maxima)。这些是在时间和频率两个轴上都比它们所有直接邻居更强烈的点。
Shazam 的算法识别这些**光谱峰值(Spectral peaks)**并丢弃其他所有内容。峰值是指在二维时间-频率网格上定义的局部区域内,其幅值 超过所有邻居的点 。
这把密集的声学谱图剥离成坐标对的稀疏散点图。因为这个散点图类似于夜空中的星星,所以它被正式称为星座图(Constellation map)。
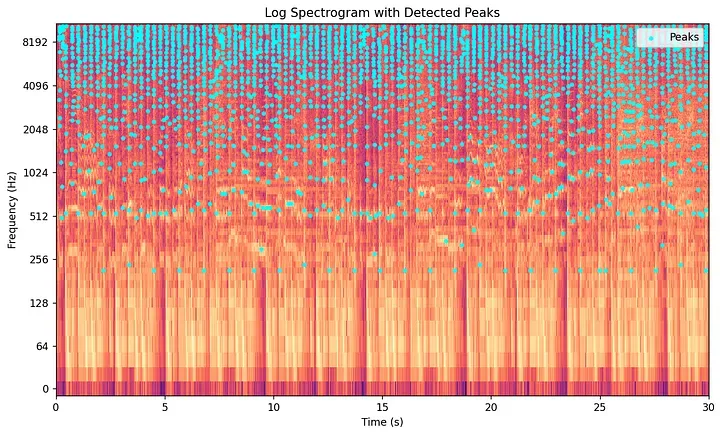
这一步提供了强大的抗噪韧性。背景闲聊或低质量的扬声器失真将能量均匀且以较低水平分散在声学谱图网格上。它们很少能产生通过阈值筛选步骤所需的主导、集中的局部峰值。存活下来的光谱峰值是声学上最强的元素,使 Shazam 即使在混乱的酒吧里也能工作。此外,仅存储峰值坐标而不是完整的声学谱图矩阵,将所需的存储容量压缩了几个数量级。
步骤 5:组合哈希——将点转化为指纹
星座图上单个孤立的点携带的熵非常低。1,400 Hz 的频率会出现在成千上万条不同的轨道上。使音频特征具有高度独特性的,是它与周围点的组合关系。
为了释放这种特异性,Shazam 的算法将每个锚点(Anchor point)与位于其前方的预定义时间-频率“目标区域”内的多个目标点(Target points)配对。对于每个唯一的“锚点-目标点”对,它通过三个结构变量计算出一个紧凑、极具辨识度的哈希值(Hash):
hash = (f_anchor, f_target, Δt)其中:
f_anchor是锚点峰值的频率f_target是目标点峰值的频率Δt = t_target − t_anchor是它们之间精确的时间差(Time delta)
为了在处理器级别最大化数据库性能,Wang 采用了一种优雅的位包装(Bit-packing)策略,将这三个变量完整地编码进一个单一的 32位无符号整数 (uint32) 中:
- 锚点频率 (): 9 位(分配 512 个独立的频率谱单元)
- 目标点频率 (): 9 位(分配 512 个独立的频率谱单元)
- 时间差 (): 14 位
- 总计: 位
这种 32 位整数结构允许系统的数据库执行硬件级别的、闪电般快速的等值查找(Equality lookups)。这些哈希值存储在一个庞大的**哈希表(Hash table)**中,并由哈希值本身作为索引。每个条目直接映射到相应的歌曲标识(Track ID)以及该锚点在录音室版本中出现的绝对时间戳:
hash → { track_id, t_anchor }由于哈希值只捕捉两个峰值之间的相对时间差(),而不是绝对时间线上的位置,因此生成的指纹完全具有平移不变性(Translation-invariant)。从一首歌曲的桥段中录制的样本,将产生与数据库母带中完全相同片段所索引出的哈希值。
步骤 6:概率匹配与时间偏移对齐
当用户触发 Shazam 时,应用程序会使用完全相同的流水线构建实时星座图,并提取一组查询哈希。然后,它向中央数据库查询匹配项。
由于在庞大的数据库中,单个 32 位哈希仍然可能发生冲突(偶然一致),因此单次匹配并不能证明任何事情。匹配引擎的独门秘籍在于相干的时间偏移对齐(Coherent time-offset alignment)。
对于在查询样本与候选数据库曲目之间找到的每一个匹配哈希,引擎都会计算该哈希在用户样本中出现的时间与在录音室曲目中出现的时间之间的时域偏移量(Offset):
如果查询样本确实属于某个特定的候选曲目,那么该样本中每一个存活下来的匹配哈希都必须产生完全相同的偏移量数值,因为它们都保留了原始录音中的相对间距。相反,来自错误曲目的随机冲突将产生毫无关联、杂乱无章的偏移量,并均匀地分散在时间线上。
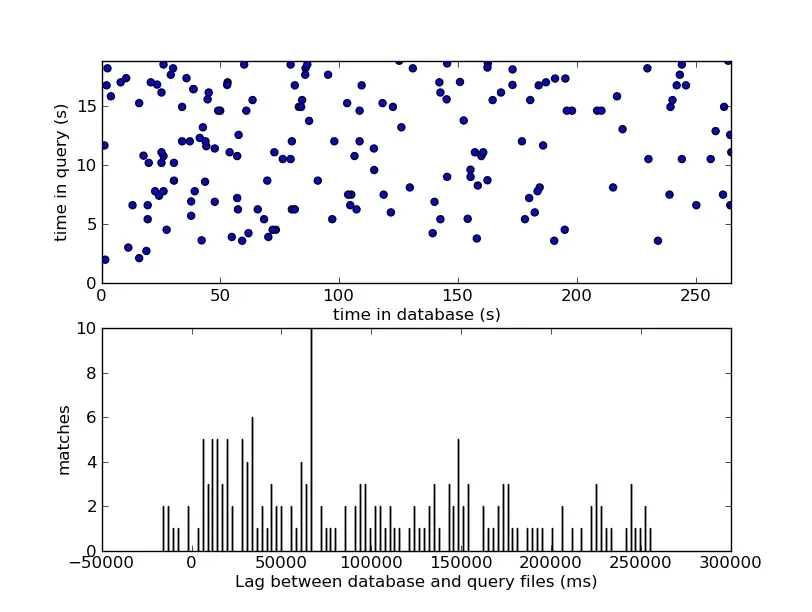
系统会为每个候选曲目 ID 构建这些计算出的偏移量的直方图,并在直方图中寻找一个陡峭且不可否认的峰值。
在直方图中寻找峰值,是在二维图表上识别对角线的离散近似,其中一个轴代表数据库时间(),另一个轴代表查询时间()。如果匹配的点完美地沿着 45 度对角线(斜率为 )排列,则证实两个音频源正以完全相同的速度推进。大量点在固定的常数偏移量()上达成一致,提供了能够完全刺破背景噪声的、在统计学上压倒性的信号。
魔法背后的概率论
让我们在数学上更直观地说明其抗噪韧性。假设一个给定的光谱峰值在嘈杂的录音环境中存活的概率为 。要成功生成一个组合哈希,其锚点峰值和目标点峰值都必须存活。单个哈希存活的联合概率为:
虽然 意味着牺牲了单个哈希的原始存活率,但这种折中在查找期间带来了指数级的回报。一个带有正确时间对齐的、存活下来的成对哈希匹配,其特异性(辨识力)远高于孤立的峰值。该算法在结构上设计为只需要一首歌总哈希值的一小部分即可确立无可争辩的匹配,从而使其能够无缝地从退化的音频中恢复识别。
技术术语表
| 术语 | 定义 |
|---|---|
| ADC | 模数转换(Analog-to-Digital Conversion)—— 将连续的声音波形转化为离散的数字样本 |
| 奈奎斯特定理 | 奈奎斯特定理(Nyquist Theorem)—— 规定信号的采样率必须达到其最高频率的两倍,才能被忠实地重构 |
| FFT | 快速傅里叶变换(Fast Fourier Transform)—— 一种用于将信号分解为频率成分的 算法 |
| STFT | 短时傅里叶变换(Short-Time Fourier Transform)—— 在滑动窗口上应用 FFT,以捕捉随时间变化的频率内容 |
| 声学谱图 | 声学谱图(Spectrogram)—— 音频信号的一种二维(时间-频率-幅值)表示形式 |
| 汉明窗 | 汉明窗(Hamming Window)—— 应用于每个 STFT 帧的平滑渐变函数,用于减少频谱泄漏 |
| 光谱峰值 | 光谱峰值(Spectral Peak)—— 声学谱图中的局部极大值 —— 即在定义区域内其幅值超过所有邻居的点 |
| 星座图 | 星座图(Constellation Map)—— 光谱峰值坐标的稀疏集合,构成了生成音频指纹的基础 |
| 组合哈希 | 组合哈希(Combinatorial Hash)—— 编码了 的 32 位哈希值 —— 音频指纹的核心单元 |
| 时间偏移对齐 | 时间偏移对齐(Time-Offset Alignment)—— 一种通过对哈希匹配偏移量进行聚类来确认歌曲相干识别的匹配技术 |
| 平移不变性 | 平移不变性(Translation Invariance)—— 指音频指纹独立于样本在歌曲中开始位置的特性 |
“无机械学习” —— 2026 年的破除迷思笔记
经典的 Avery Wang 算法是纯粹、确定性的一维/二维信号处理和快速哈希的杰作。它不包含任何神经网络、任何权重,也没有机器学习训练模型。
然而,从 2026 年的视角审视这一架构,非常值得补充一个小小的现代注脚。虽然核心匹配框架和指纹索引仍然锚定在这些精确的数学原理上,但现代 Shazam(在苹果生态系统下运行)已经演变成一个混合系统。轻量级、高度优化的深度学习模型 —— 特别是卷积神经网络 (CNN) —— 现在经常被部署在初始的信号摄取阶段。这些神经网络模型充当超高效的前端过滤器,在音频进入星座图映射阶段之前,消除极端的外界咖啡馆噪音、隔离人声或进行声源分离。
即使加入了现代 AI 的扩展,该系统的核心重任、匹配速度以及最终的可靠性,依然完全建立在二十多年前奠定的美丽数学基石之上。下一次当你按下那个按钮时,你正在见证傅里叶变换执行某种真正超越时间的代码。
