
あなたはカフェに座っています。スピーカーからある曲が流れてきました。聞き覚えはあるものの、どうしても曲名が思い出せません。そこでスマホを取り出し、Shazamをタップします。すると5秒もしないうちに、正確な曲名、アーティスト名、アルバム情報が表示されます。歌詞を入力することも、ハミングすることも、検索することもなく、ただ騒がしい店内の生の音を拾っただけです。
これはまるで魔法のように思えますが、決して魔法ではありません。そのタップの裏側には、応用数学において最もエレガントなアルゴリズムの一つが隠されています。それは、背景ノイズや性能の低いマイク、途切れた録音であっても高い信頼性で動作する、信号処理、組み合わせハッシュ、そして確率的マッチングを駆使して構築されたシステムです。その仕組みを詳しく見ていきましょう。
略歴:パブでのひらめきからAppleによる買収まで
物語は1999年、Chris Barton(当時カリフォルニア大学バークレー校(UC Berkeley)のMBA学生)が、ロンドンのバーで流れる曲が分からず、もどかしい思いをしたことから始まります。彼はシンプルながらも急進的なアイデアを思いつきました。「もし、空気中の音を聴くだけで、スマホが自動的に曲を識別してくれたらどうだろう?」
Bartonは、Philip Inghelbrecht、Dhiraj Mukherjeeと共にShazam Entertainment Ltdを共同設立しました。チームにとって決定的な転機となったのは、スタンフォード大学のProfessor Julius Smithから、デジタル信号処理の博士号を持つAvery Wangを紹介されたことでした。Wangのプロジェクトに対する最初の見立ては、「そんなのは不可能だ」という容赦のないものでした。当時の課題は膨大でした。システムは、初期の携帯電話の悪名高き低音質な音声チャネルを介して、周囲のノイズを拾いながら、数百万曲のスケールからリアルタイムで音楽を識別する必要があったからです。
Wangは諦めかけましたが、2000年6月、ついにブレイクスルーを果たします。これこそが、今日までShazamを支え続けている「音声フィンガープリント(音声指紋)」システムの誕生の瞬間でした。
2002年、このサービスは英国で開始されました。当時はアプリとしてではなく、4桁の電話番号(2580)のサービスとしてスタートしました。ユーザーはその番号に電話をかけ、スマホをスピーカーにかざすと、曲情報を記載したSMSが届くという仕組みでした。2580 という番号の選択は意図的なものでした。古い携帯電話のキーパッドを見ると、これらのキーは中央に縦一列に並んでおり、騒がしいパブの中で移動しながらでも非常にダイヤルしやすかったためです。ローンチ時のデータベースには100万曲が登録されており、応答には約15秒かかっていました。
2008年にAppleがApp Storeをローンチすると、状況は一夜にして一変しました。Shazamは最初期に利用可能なアプリの一つとなり、ユーザーの利用障壁は完全に消え去りました。2022年までに、アプリのダウンロード数は20億回を超えています。Appleは2017年12月にShazamの買収合意を正式発表し、2018年9月に推定4億ドルで買収を完了しました。
Wangが2003年に発表した画期的な論文 “An Industrial-Strength Audio Search Algorithm” は、今なおシステムの基礎的なアーキテクチャであり続けています。
根本的な課題:なぜ音声識別は難しいのか
解決策を検証する前に、ノイズ混じりの10秒間のサンプルから曲を識別することが、計算科学的にどれほど困難な問題であるかを正確に理解しておく必要があります。
課題は大きく分けて3つあります:
- スケール: Shazamのデータベースには数億曲が登録されています。サンプルから生成されたフィンガープリントは、わずか数秒以内にこの膨大なカタログ全体と照合されなければなりません。
- ノイズ: キャプチャされた音声には、背景の話し声、室内の残響、低品質なマイクによる圧縮、伝送時のアーティファクトなどが含まれています。これらは、データベースにある洗練されたスタジオ録音には一切存在しないものです。
- 時間的オフセット(時間のズレ): サンプルは曲の あらゆる 位置(イントロ、ブリッジ、アウトロなど)から切り取られる可能性があるため、マッチングにおいて楽曲内の一致する絶対的な位置に依存することはできません。
生の波形(ウェーブフォーム)を単純に比較するという素朴なアプローチでは、これら3つのテストすべてに瞬時に失敗します。録音されたサンプルの波形とスタジオトラックの波形は、直接相関させるにはあまりにも異なりすぎているからです。そのため、音声をよりスマートに表現する方法が必要になります。
ステップ 1:信号のキャプチャと最適化
ユーザーがShazamをタップすると、アプリはデバイスのマイクを通じて5〜10秒の音声サンプルを録音します。このアナログ音声(空気中を伝わる連続的な圧力波)は、**A/D変換(アナログ-デジタル変換:ADC)**と呼ばれるプロセスを経てデジタル信号に変換されます。
標準的な高忠実度(ハイファイ)オーディオは、通常毎秒44,100サンプル(44.1 kHz)で録音されますが、Shazamはメモリと処理能力を節約するために、極めて巧妙なダウンサンプリングと最適化の戦略を採用しています。入力された音声は、その後の数学的処理が行われる前に、まず 8 kHz(場合によっては11 kHz)にダウンサンプリングされ、ステレオから単一の モノラルチャネル に変換されます。
なぜこの最適化がこれほど見事に機能するのでしょうか?人間の聴覚は最大20 kHzまで及びますが、ポップミュージックを特徴づける独自の「エネルギッシュな」特性(ボーカル、パーカッションの過渡応答、支配的な倍音構造など)の大部分は、4 kHz以下に余裕で収まります。**標本化定理(ナイキスト・シャノンの定理)**によれば、8 kHzのサンプリングレートがあれば、4 kHzまでのすべての周波数を数学的に完全にキャプチャし、復元することができます。この最適化ステップにより、識別を可能にする極めて重要な特徴を損なうことなく、アルゴリズムが毎秒処理しなければならないデータ量を劇的に圧縮しているのです。
ステップ 2:フーリエ変換 — 音を周波数に分解する
Shazamを可能にしている基盤となる数学的ツールは、**離散フーリエ変換 (DFT)であり、実務においては計算が最適化された高速フーリエ変換 (FFT)**を介して実装されています。
DFTは、時間領域の信号(振幅のシーケンス)を取り込み、それを構成要素である周波数成分に分解します。平たく言えば、ある瞬間に音が どれだけ大きいか ではなく、どの周波数 がどれだけの強度で存在しているかを教えてくれるものです。
数学的には、長さ の信号 のDFTは次のように美しく表現されます。
ここで:
- は入力される時間領域の信号(サンプル における振幅)
- は周波数ビン における複素数出力(周波数領域)
- は回転する単位ベクトルを表す複素指数関数
- は周波数 における大きさ(振幅)を示す
FFTは、この変換を素朴なアプローチの ではなく の時間で計算するため、一般的な市販のハードウェア上でもリアルタイムの音声処理を十分に可能にします。
しかし、サンプル全体に対して一度だけFFTを実行するアプローチには問題があります。音楽は定常的ではない(周波数が時間とともにダイナミックに変化する)ということです。単一のFFTでは、ギター、ピアノ、ベースの音が「どこかに」存在していることは分かっても、それぞれの音がいつ鳴ったかという時間的な文脈が完全に失われてしまいます。
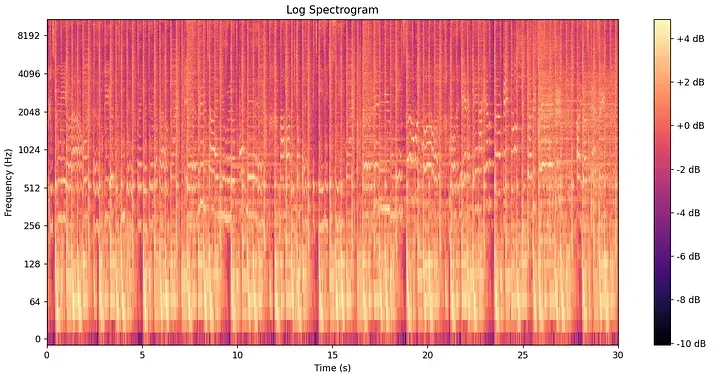
ステップ 3:短時間フーリエ変換とスペクトログラム
周波数が時間とともにどのように変化するかを捉えるため、Shazamは**短時間フーリエ変換 (STFT)を適用します。音声クリップ全体に対して一度に巨大なFFTを実行するのではなく、アルゴリズムは一般的に10〜30ミリ秒幅の小さな分析窓(ウィンドウ)**を信号に沿ってスライドさせ、各離散区間でFFTを計算します。
その結果、以下のような2次元(2D)の表現が得られます:
- 横軸: 時間(各窓の位置)
- 縦軸: 周波数(各FFTの周波数ビン)
- 色/強度: 振幅(その瞬間におけるその周波数の大きさ)
この2次元構造は**スペクトログラム**と呼ばれ、フィンガープリント(指紋)を生成するためのコアなランドスケープとして機能します。
矩形窓の急激な遮断によって、一つのシャープな周波数ビンのエネルギーが隣接するビンに漏れ出す**スペクトル漏れと呼ばれるアーティファクトを防ぐため、STFTはHamming window**関数を適用します。この滑らかなベル型の曲線が、各分析フレームの端を減衰させます。ハミング窓 は数学的に以下のように定義されます:
楽曲のスペクトログラムは、その音響的なフィンガープリントのグリッドを完全に捉えます。しかし、数百万曲ものデータベースと生の行列データをそのまま比較することは、計算量的に不可能に近いです。そのため、さらなる抽象化が必要になります。
ステップ 4:星座マップ(コンステレーションマップ) — スペクトルピークの抽出
ここに、Avery Wangの最大の洞察が光っています。スペクトログラムの大部分は、背景ノイズ、残響、そしてエネルギーの低い情報で占められています。音楽において音響的に意味のある要素(キックドラムの瞬間的なアタック、ギターコードの鳴り始め、あるいはボーカルメロディのピークなど)は、スペクトログラム上の**局所的な極大値(ローカルマキシマ)**として現れます。これらは、時間と周波数の両方の軸において、直近の周囲のどの点よりも強度が強い点のことです。
Shazamのアルゴリズムは、これらのスペクトルピークを特定し、それ以外のデータをすべて破棄します。ピークとは、2次元の時間-周波数グリッド上で定義された一定の局所領域内において、その大きさ がすべての近傍の値を上回る点 のことです。
これにより、高密度なスペクトログラムは、座標対のまばらな散布図へと削ぎ落とされることになります。この散布図が夜空に輝く星のように見えることから、正式に**星座マップ(コンステレーションマップ)**と呼ばれています。
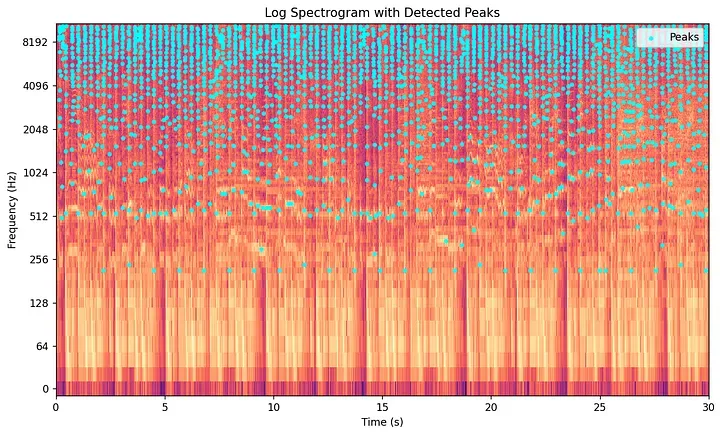
このステップにより、強力なノイズ耐性が得られます。周囲の話し声や低品質なスピーカーによる歪みは、スペクトログラムのグリッド全体に均等かつ低いレベルでエネルギーを分散させます。そのため、閾値処理のステップを通過するような、支配的で集中した局所的ピークを生成することは滅滅にありません。生き残ったスペクトルピークは、音響的に最も強い要素であるため、Shazamは騒がしいバーの中でも確実に機能することができます。さらに、スペクトログラムの完全な行列データの代わりにピークの座標のみを保存することで、必要なストレージ容量を数桁も圧縮することが可能になります。
ステップ 5:組み合わせハッシュ — 点をフィンガープリントに変換する
星座マップ上の孤立した1つの点だけでは、情報量(エントロピー)が非常に低いです。たとえば1,400 Hzという周波数は、何千もの異なる楽曲に登場します。オーディオのシグネチャを極めてユニークなものにしているのは、周囲の点との組み合わせ関係です。
この固有性を引き出すため、Shazamのアルゴリズムは各アンカーポイント(基準点)を、その前方にある事前に定義された時間-周波数領域(「ターゲットゾーン」)内の複数のターゲットポイント(標的点)とペアリングします。そして、それぞれのユニークな「アンカー・ターゲット」のペアに対して、次の3つの構造的変数からコンパクトで識別性の高いハッシュを算出します:
hash = (f_anchor, f_target, Δt)ここで:
f_anchorはアンカーピークの周波数f_targetはターゲットピークの周波数Δt = t_target − t_anchorは両者の間の正確な時間差(タイムデルタ)
プロセッサレベルでのデータベースパフォーマンスを最大限に引き出すため、Wangはこれら3つの要素すべてを単一の**符号なし32ビット整数(uint32)**にエンコードする、洗練されたビットパッキング戦略を採用しました:
- アンカーの周波数 (): 9ビット(512個の個別の周波数ビンを割り当て)
- ターゲットの周波数 (): 9ビット(512個の個別の周波数ビンを割り当て)
- 時間差 (): 14ビット
- 合計: ビット
この32ビット整数構造により、システムのデータベースはハードウェアレベルでの超高速な等価性ルックアップ(一致検索)を実行できるようになります。これらのハッシュは、ハッシュ値そのものをインデックスとした巨大なハッシュテーブルに格納されます。各エントリは、対応する楽曲の識別情報(トラックID)と、スタジオバージョンにおいてそのアンカーポイントが発生した絶対的なタイムスタンプに直接マッピングされます:
hash → { track_id, t_anchor }ハッシュは、絶対的な時間軸上の配置ではなく、2つのピーク間の相対的な時間差()のみをキャプチャするため、生成されるフィンガープリントは完全に**平行移動不変(タイムシフト不変)**になります。楽曲のブリッジ(大サビなど)から録音されたサンプルは、データベースのマスタリング音源の全く同じセクションからインデックス化されたハッシュと、完全に同一のハッシュを生成します。
ステップ 6:確率的マッチングとタイムオフセットのアライメント
ユーザーがShazamを起動すると、アプリはこれと全く同じパイプラインを使用して、リアルタイムで星座マップを構築し、クエリハッシュのセットを抽出します。その後、中央データベースに対してマッチングのクエリを実行します。
膨大なデータベース内では、個々の32ビットハッシュが衝突(偶然一致)する可能性があるため、単一のハッシュが一致しただけでは何も証明されません。マッチングエンジンの真の秘訣は、**コヒーレントなタイムオフセットのアライメント(時間差の整合性チェック)**にあります。
クエリサンプルと候補となるデータベース楽曲との間で一致するハッシュが見つかるたびに、エンジンは、そのハッシュが「ユーザーのサンプル内に現れた時間」と「スタジオトラック内に現れた時間」の間の時間的*オフセット(ズレ)*を計算します:
もしクエリサンプルが本当に特定の候補曲のものであるならば、そのサンプルから得られた生き残ったすべてのハッシュマッチは、全く同じオフセット値を返すはずです。なぜなら、それらはすべて元の録音から相対的な間隔を維持しているからです。逆に、誤った楽曲からのランダムな衝突(偶然の一致)は、時間軸上に一様に分散した、相関のない無秩序なオフセットを生成することになります。
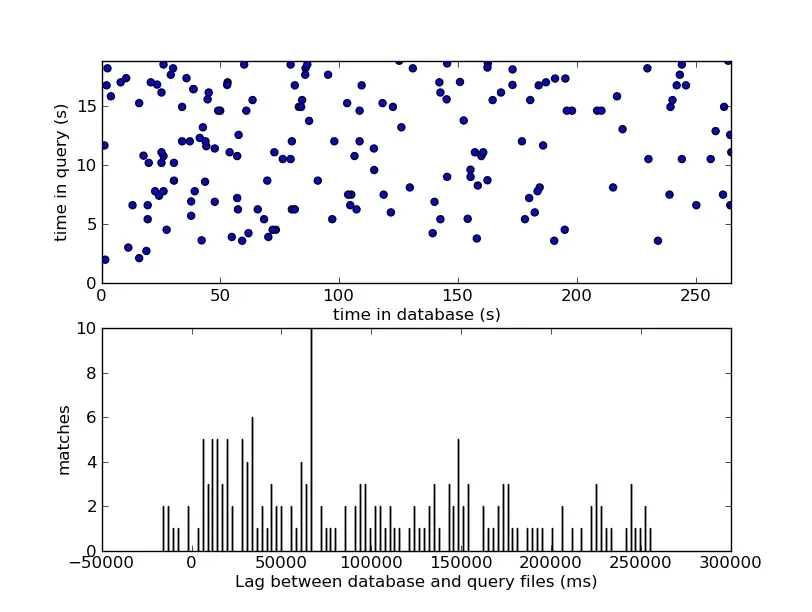
システムは、候補となる楽曲IDごとに、これらの計算されたオフセットのヒストグラムを構築し、ヒストグラム内のシャープで明白なピークを探索します。
ヒストグラムの中にピークを見つけるという行為は、一方の軸がデータベース時間()、もう一方の軸がクエリ時間()を表す2次元グラフ上で、対角線を特定することの離散的な近似です。一致した点が45度の対角線(傾き )に沿って完璧に整列していれば、両方の音源が全く同じ速度で進行していることが証明されます。特定の一定のオフセット()で一致する点の膨大なクラスタ(集まり)が存在することは、背景ノイズを完全に突き抜ける、統計的に圧倒的なシグナルとなります。
魔法の裏にある確率論
ノイズに対する堅牢性を数学的に明示してみましょう。あるスペクトルピークが、ノイズの多い録音環境を生き残る確率を と仮定します。組み合わせハッシュが正常に生成されるためには、そのアンカーピークとターゲットピークの両方が生き残る必要があります。単一のハッシュが生き残る結合確率は次のようになります:
であるため、個々のハッシュの単純な生存率という点では犠牲を払っているように見えますが、このトレードオフはルックアップ(検索)時に指数関数的なリターンをもたらします。適切な時間アライメント(整合性)を持った、一対の生き残ったハッシュマッチは、孤立した1つのピークよりも遥かに高い固有性(識別力)を持ちます。このアルゴリズムは構造上、確実なマッチングを確立するために楽曲の全ハッシュのわずかな割合さえあれば事足りるように設計されているため、劣化した音声からでもシームレスに楽曲を復元して識別することができるのです。
技術用語集
| 用語 | 定義 |
|---|---|
| ADC | アナログ-デジタル変換(Analog-to-Digital Conversion)。連続的な音響波を離散的なデジタルサンプルに変換する処理。 |
| ナイキストの定理 | 信号を忠実に復元するためには、その信号に含まれる最高周波数の2倍以上のサンプリングレートで標本化しなければならないという定理。 |
| FFT | 高速フーリエ変換(Fast Fourier Transform)。信号を周波数成分に分解するための の計算量を持つアルゴリズム。 |
| STFT | 短時間フーリエ変換(Short-Time Fourier Transform)。スライド窓を適用しながらFFTを実行し、時間とともに変化する周波数成分を捉える手法。 |
| スペクトログラム | 音声信号を「時間・周波数・振幅」の3つの要素で表した2次元の視覚的表現。 |
| ハミング窓 | スペクトル漏れを低減するために、STFTの各フレームの両端を滑らかに減衰させる窓関数。 |
| スペクトルピーク | スペクトログラムにおける局所的な極大値。定義された一定領域内で、周囲のどの点よりも振幅(大きさ)が上回っている点。 |
| 星座マップ | スペクトルピークの座標のみを抽出したまばらなデータセット。フィンガープリント生成の基礎となる。 |
| 組み合わせハッシュ | をエンコードした32ビットのハッシュ。フィンガープリントのコアとなる最小単位。 |
| タイムオフセット・アライメント | ハッシュが一致した時間差(オフセット)を集計(クラスタリング)し、楽曲の一致に整合性があるかを検証するマッチング技術。 |
| 平行移動不変性 | フィンガープリント(指紋)の特性が、楽曲内のどの位置からサンプルが開始されたかに依存しない(影響を受けない)性質。 |
「機械学習は使われていない」 — 2026年における誤解の打破
エイブリー・ワン(Avery Wang)氏が考案したクラシックなアルゴリズムは、純粋かつ決定論的な1次元・2次元の信号処理と、高速なハッシュ化を組み合わせた、応用数学の傑作です。そこにはニューラルネットワークも、重みの調整も、機械学習による学習モデルも一切含まれていません。
しかし、2026年の視点からこのアーキテクチャを眺めると、現代的な補足を少し書き加える必要があります。コアとなるマッチングの枠組みやフィンガープリントのインデックス化は、今なお当時の美しい数学的原理に忠実ですが、Appleのエコシステム下で運用されている現在のShazamは、ハイブリッドなシステムへと進化を遂げています。現在では、音声が星座マップの生成フェーズに入る前の段階(初期の信号取り込みフェーズ)において、軽量で高度に最適化されたディープラーニングモデル、具体的には**畳み込みニューラルネットワーク(CNN)**が頻繁に投入されています。これらのニューラルモデルは超効率的なフロントエンド・フィルターとして機能し、カフェの極端な外部ノイズを排除したり、ボーカルを孤立させたり、音源分離を実行したりしています。
たとえ現代的なAIの拡張機能が追加されたとしても、このシステムの中核となる最も重い処理、マッチングの圧倒的なスピード、そして最終的な信頼性は、今なお20年以上前に築かれた美しい数学的基盤の上に成り立っています。次にあなたがShazamのボタンをタップするとき、あなたはフーリエ変換が、時代を超越した真の「魔法」を実行する瞬間を目撃しているのです。
