
Sjedite u kafiću. Iz zvučnika dopire pjesma — znate da vam je poznata, ali imena se nikako ne možete sjetiti. Izvadite telefon, dodirnete Shazam i u roku od pet sekundi saznate točan naziv pjesme, izvođača i album. Bez tipkanja teksta, bez pjevušenja, bez pretraživanja. Samo čisti zvuk uhvaćen u bučnoj prostoriji.
Ovo djeluje poput magije. Ali nije. Iza tog jednog dodira krije se jedan od najelegantnijih algoritama u primijenjenoj matematici — sustav izgrađen na obradi signala, kombinatornom hashiranju i probabilističkom sparivanju koji pouzdano radi čak i uz pozadinsku buku, loše mikrofone i skraćene snimke. Evo kako to funkcionira.
Kratka povijest: Od ideje u pubu do Appleove akvizicije
Priča počinje 1999. godine, kada se Chris Barton — student MBA-a na sveučilištu UC Berkeley — našao u frustrirajućoj situaciji u jednom londonskom baru, ne uspijevajući identificirati pjesmu koja je svirala s razglasa. Sinula mu je jednostavna, ali radikalna ideja: što ako bi telefon to mogao učiniti umjesto vas, samo na temelju zvuka iz okoline?
Barton je suosnovao Shazam Entertainment Ltd zajedno s Philipom Inghelbrechtom i Dhirajom Mukherjeejem. Ključno pojačanje stiglo je kada ih je profesor Julius Smith sa Stanforda usmjerio na Averyja Wanga, doktora znanosti u području digitalne obrade signala. Wangova prva procjena projekta bila je izravna: “To je nemoguće.” Izazovi su bili golemi — sustav je morao prepoznavati glazbu u stvarnom vremenu, kroz ambijentalnu buku, na ljestvici od milijun pjesama, i to preko mobilnih kanala koji su na ranim mobilnim uređajima bili ozloglašeno loše kvalitete.
Wang je zamalo odustao. No, u lipnju 2000. godine uspio je riješiti problem, izumivši sustav za izradu audio otisaka (audio fingerprinting) koji pokreće Shazam i danas.
U 2002. godini usluga je pokrenuta u Velikoj Britaniji — ne kao aplikacija, već kao četveroznamenkasti telefonski broj (2580). Korisnici bi nazvali taj broj, usmjerili telefon prema zvučniku i primili SMS poruku s podacima o pjesmi. Izbor broja 2580 bio je namjeran: te su tipke raspoređene u ravnu okomitu liniju na sredini tipkovnice starih mobitela, što je olakšavalo tipkanje dok ste u pokretu u glasnom pubu. Baza podataka na samom početku sadržavala je milijun pjesama, a sustavu je trebalo oko 15 sekundâ za odgovor.
Kada je Apple 2008. godine lansirao App Store, sve se promijenilo preko noći. Shazam je bio jedna od prvih dostupnih aplikacija i svaka prepreka za korisnike je nestala. Do 2022. godine aplikacija je preuzeta više od 2 milijarde puta. Apple je službeno najavio akviziciju Shazama u prosincu 2017. godine, a ugovor je službeno zaključen u rujnu 2018. za procijenjenih 400 milijuna dolara.
Algoritam koji je Avery Wang objavio u svom revolucionarnom radu iz 2003. — “An Industrial-Strength Audio Search Algorithm” — i danas čini temeljnu arhitekturu ovog sustava.
Temeljni problem: Zašto je prepoznavanje zvuka teško
Prije nego što analiziramo rješenje, važno je razumjeti zašto je točno prepoznavanje pjesme iz bučnog uzorka od 10 sekundi težak računalni problem.
Izazov je trostruk:
- Ljestvica (Skalabilnost). Shazamova baza podataka sadrži stotine milijuna pjesama. Audio otisak iz uzorka mora se uskladiti s cijelim ovim katalogom u nekoliko sekundi.
- Buka. Snimljeni zvuk sadrži pozadinski govor, akustiku prostorije, kompresiju mikrofona niske kvalitete i artefakte prijenosa — od čega ništa nije prisutno u izvornom studijskom zapisu u bazi podataka.
- Vremenski pomak (Temporal offset). Uzorak se može uzeti s bilo koje točke u pjesmi — s početka, prijelaza (bridgea), završetka — tako da se sparivanje ne može oslanjati na apsolutnu poziciju unutar zapisa.
Naivan pristup — uspoređivanje sirovih valnih oblika (waveforms) — pao bi na sva tri ispita istovremeno. Valni oblik vašeg snimljenog uzorka i valni oblik studijske pjesme jednostavno su previše različiti da bi se mogli izravno povezati. Potrebna je pametnija reprezentacija zvuka.
Korak 1: Hvatanje i optimizacija signala
Kada dodirnete Shazam, aplikacija snima audio uzorak od 5 do 10 sekundi putem mikrofona vašeg uređaja. Ovaj analogni zvuk — kontinuirani val pritiska koji putuje zrakom — pretvara se u digitalni signal procesom koji se naziva analogno-digitalna pretvorba (ADC).
Dok se standardni audio visoke vjernosti (hi-fi) obično snima pri 44.100 uzoraka u sekundi (44,1 kHz), Shazam koristi genijalnu strategiju smanjenja frekvencije uzorkovanja (downsampling) i optimizacije kako bi uštedio memoriju i procesorsku snagu. Dolazni zvuk se spušta na frekvenciju od 8 kHz (ili ponekad 11 kHz) i pretvara iz sterea u jedan mono kanal prije nego što se dogodi bilo kakva daljnja matematička obrada.
Zašto ova optimizacija tako dobro funkcionira? Ljudski sluh seže do 20 kHz, ali velika većina jedinstvenih “energetskih” karakteristika koje razlikuju popularnu glazbu — kao što su vokali, perkusivni tranzijenti i dominantne harmonijske strukture — nalazi se udobno ispod 4 kHz. Prema Nyquist-Shannonovom teoremu uzorkovanja, brzina uzorkovanja od 8 kHz matematički je dovoljna za savršeno hvatanje i rekonstrukciju svih frekvencija do 4 kHz. Ovaj korak optimizacije drastično komprimira količinu podataka koje algoritam mora obraditi svake sekunde, bez gubitka ključnih značajki potrebnih za identifikaciju.
Korak 2: Fourierova transformacija — Rastavljanje zvuka na frekvencije
Temeljni matematički alat koji omogućuje Shazam jest Diskretna Fourierova transformacija (DFT), koja se u praksi implementira putem računalno optimizirane Brze Fourierove transformacije (FFT).
DFT uzima signal iz vremenske domene — sekvencu amplituda — i rastavlja ga na njegove sastavne frekvencijske komponente. Jednostavnim rječnikom: ne govori vam koliko je glasan zvuk u nekom trenutku, već koje su frekvencije prisutne i kojim intenzitetom.
Matematički, DFT signala duljine prekrasno se izražava u LaTeX formatu kao:
Gdje je:
- ulazni signal u vremenskoj domeni (amplituda na uzorku )
- kompleksni izlaz u frekvencijskoj domeni na frekvencijskom mjestu (binu)
- kompleksni eksponent koji predstavlja rotirajući jedinični vektor
- daje magnitudu (amplitudu) na frekvenciji
FFT izračunava ovu transformaciju u složenosti umjesto naivnih , što obradu zvuka u stvarnom vremenu čini iznimno izvedivom na uobičajenom hardveru široke potrošnje.
Problem s jednom FFT transformacijom preko cijelog uzorka je taj što glazba nije stacionarna — frekvencije se dinamički mijenjaju tijekom vremena. Jedna FFT transformacija rekla bi vam da su gitara, klavir i bas prisutni negdje u snimci, ali bi potpuno izgubila vremenski kontekst o tome kada se koja nota pojavljuje.
Korak 3: Kratkotrajna Fourierova transformacija i spektrogram
Kako bi uhvatio način na koji se frekvencije mijenjaju tijekom vremena, Shazam primjenjuje Kratkotrajnu Fourierovu transformaciju (STFT). Umjesto pokretanja jedne masivne FFT transformacije preko cijelog isječka, algoritam pomiče mali analitički prozor — obično širine 10–30 milisekundi — duž signala i izračunava FFT na svakom diskretnom intervalu.
Rezultat je dvodimenzionalni (2D) prikaz:
- Horizontalna os: Vrijeme (svaka pozicija prozora)
- Vertikalna os: Frekvencija (svako pojedinačno frekvencijsko mjesto/bin FFT-a)
- Boja/intenzitet: Amplituda (magnituda te frekvencije u tom određenom trenutku)
Ova 2D struktura naziva se spektrogram i služi kao temeljni krajolik za izradu audio otiska.
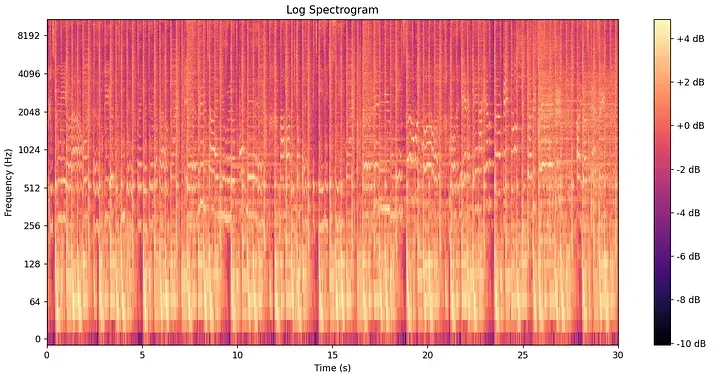
Kako bi se spriječio artefakt poznat kao spektralno curenje (spectral leakage) — gdje se energija iz jednog oštrog frekvencijskog binarca “prelijeva” u susjedne binarce zbog naglih rezova pravokutnog prozora — STFT primjenjuje funkciju Hammingovog prozora. Ova glatka zvonolika krivulja ublažava i sužava rubove svakog analitičkog okvira. Hammingov prozor matematički je definiran kao:
Spektrogram pjesme bilježi njezinu potpunu mrežu akustičnog otiska. Međutim, uspoređivanje sirovih matrica u bazi podataka s milijunima pjesama i dalje bi bilo računalno neizvedivo i tromo. Potrebna je dodatna apstrakcija.
Korak 4: Konstelacijska mapa — Izdvajanje spektralnih vrhova
Ovdje dolazi do izražaja ključni uvid Averyja Wanga. Veći dio spektrograma sastoji se od pozadinske buke, jeke i niskoenergetskih ispuna. Akustički značajni elementi u glazbi — prolazni udarac bas bubnja, početak akorda gitare ili vrhunac vokalne melodije — manifestiraju se kao lokalni maksimumi u spektrogramu. To su točke koje su intenzivnije od svih svojih neposrednih susjeda i u vremenu i u frekvenciji.
Shazamov algoritam identificira te spektralne vrhove (spectral peaks) i odbacuje sve ostalo. Vrh je točka čija magnituda premašuje sve susjedne točke unutar definiranog lokalnog područja na 2D vremensko-frekvencijskoj mreži.
Time se gusti spektrogram svodi na rijetki dijagram raspršenosti (scatter plot) koordinatnih parova. Budući da ovaj dijagram podsjeća na zvijezde na noćnom nebu, formalno se naziva konstelacijska mapa.
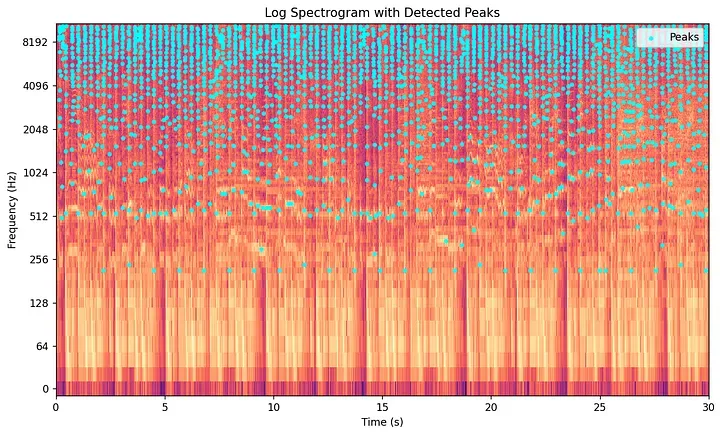
Ovaj korak pruža moćnu otpornost na buku. Pozadinski govor ili izobličenja zvučnika niske kvalitete ravnomjerno raspoređuju energiju i to na nižim razinama po mreži spektrograma. Oni rijetko generiraju dominantne, koncentrirane lokalne vrhunce koji su potrebni za prolazak kroz prag selekcije. Spektralni vrhovi koji prežive akustički su najjači elementi, što Shazamu omogućuje rad čak i u kaotičnom kafiću ili baru. Osim toga, pohranjivanje samo koordinata vrhova umjesto cijelih matrica spektrograma smanjuje potreban kapacitet pohrane za nekoliko redova veličine.
Korak 5: Kombinatorno hashiranje — Pretvaranje točaka u audio otiske
Sama, izolirana točka na konstelacijskoj mapi nosi vrlo malo entropije. Frekvencija od 1400 Hz pojavljuje se u tisućama različitih pjesama. Ono što audio potpis čini iznimno prepoznatljivim jest njegov kombinatorni odnos s okolnim točkama.
Kako bi otključao tu specifičnost, Shazamov algoritam povezuje svaku usidrenu točku (anchor point) s više ciljanih točaka (target points) koje iz izbornog prozora padaju unutar unaprijed definirane vremensko-frekvencijske “ciljane zone” (target zone) smještene ispred nje. Za svaki jedinstveni par sidro-cilj, algoritam izračunava kompaktan, visoko diskriminativan hash iz triju strukturnih varijabli:
hash = (f_anchor, f_target, Δt)Gdje je:
f_anchorfrekvencija usidrenog vrha (sidra)f_targetfrekvencija ciljanog vrhaΔt = t_target − t_anchorprecizna vremenska razlika (delta) između njih
Kako bi se maksimizirale performanse baze podataka na razini procesora, Wang je upotrijebio elegantnu strategiju pakiranja bitova (bit-packing) kako bi cijeli ovaj trojac kodirao u jedan 32-bitni neoznačeni cijeli broj (uint32):
- Frekvencija sidra (): 9 bitova (dodjeljuje 512 zasebnih frekvencijskih mjesta/binova)
- Frecuencija cilja (): 9 bitova (dodjeljuje 512 zasebnih frekvencijskih mjesta/binova)
- Vremenska razlika (): 14 bitova
- Ukupno: bita
Ova struktura 32-bitnog cijelog broja omogućuje bazi podataka sustava obavljanje munjevito brzih pretraživanja jednakosti na razini hardvera. Ti se hashevi pohranjuju u masivnu hash tablicu, indeksiranu prema samoj vrijednosti hasha. Svaki unos mapira se izravno na odgovarajući identifikacijski broj pjesme (track ID) i apsolutnu vremensku oznaku (timestamp) kada se usidrena točka pojavila u studijskoj verziji:
hash → { track_id, t_anchor }Budući da hash bilježi samo relativnu vremensku razliku () između dvaju vrhova, a ne apsolutni smještaj na vremenskoj traci, rezultirajući audio otisak potpuno je invarijantan na translaciju (pomak). Uzorak snimljen s prijelaza (bridgea) pjesme proizvest će identične hasheve onima koji su indeksirani iz tog točnog segmenta u matičnoj bazi podataka.
Korak 6: Probabilističko sparivanje i poravnanje vremenskog pomaka
Kada korisnik pokrene Shazam, aplikacija u stvarnom vremenu gradi konstelacijsku mapu i izvlači skup upitnih hasheva koristeći potpuno isti ovaj proces. Zatim pretražuje središnju bazu podataka tražeći podudaranja.
Budući da pojedinačni 32-bitni hashevi i dalje mogu dovesti do kolizije (preklapanja) unutar goleme baze podataka, jedno podudaranje ne dokazuje ništa. Tajni sastojak pokretača za sparivanje leži u koherentnom poravnanju vremenskog pomaka (time-offset alignment).
Za svaki podudarni hash koji se pronađe između upitnog uzorka i kandidatske pjesme iz baze podataka, sustav izračunava vremenski pomak (offset) između pojavljivanja tog hasha u korisnikovu uzorku u odnosu na njegovo pojavljivanje u studijskoj pjesmi:
Ako upitni uzorak doista pripada određenoj kandidatskoj pjesmi, svako pojedino preživjelo podudaranje hasha iz tog uzorka mora dati točno istu vrijednost pomaka, jer svi oni zadržavaju svoj relativni razmak iz originalne snimke. Nasuprot tome, slučajne kolizije kod pogrešnih pjesama generirat će nepovezane, kaotične pomake ravnomjerno raspršene duž vremenske trake.
Sustav gradi histogram tih izračunatih pomaka za svaki ID kandidatske pjesme i traži oštar, neosporan vrh u histogramu.
Pronalaženje vrha u histogramu diskretna je aproksimacija identificiranja dijagonalne linije na 2D grafikonu gdje jedna os predstavlja vrijeme baze podataka (), a druga vrijeme upita (). Ako se podudarne točke savršeno poravnaju duž dijagonalne linije od 45 stupnjeva (nagib ), to potvrđuje da oba audio izvora napreduju potpuno istom brzinom. Značajan klaster točaka koje se podudaraju na fiksnom, konstantnom pomaku () pruža statistički nadmoćan signal koji potpuno nadjačava pozadinsku buku.
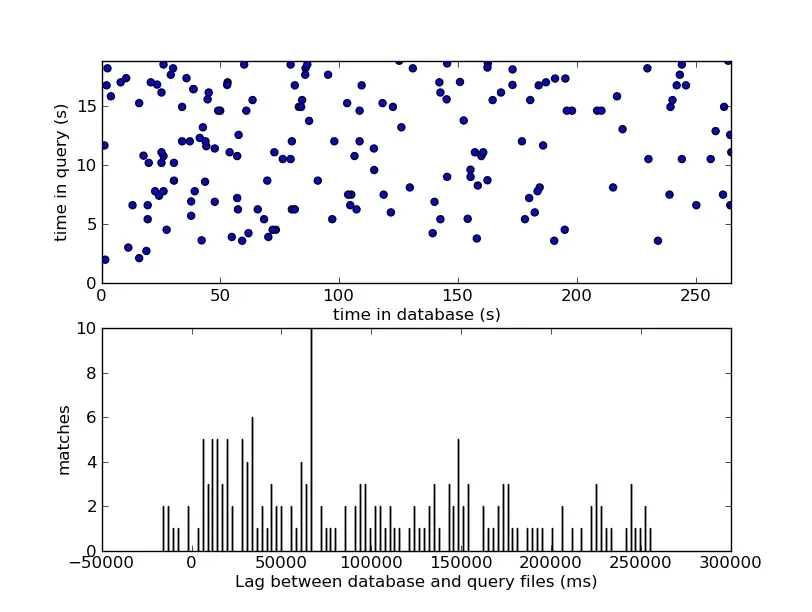
Vjerojatnost iza magije
Učinimo otpornost na buku matematički eksplicitnom. Pretpostavimo da određeni spektralni vrh ima vjerojatnost da preživi u bučnom okruženju snimanja. Kako bi se kombinatorni hash uspješno generirao, moraju preživjeti i njegov usidreni i njegov ciljani vrh. Zajednička vjerojatnost da će jedan hash preživjeti iznosi:
Iako predstavlja žrtvu u sirovoj stopi preživljavanja za pojedinačne hasheve, ovaj se kompromis eksponencijalno isplaćuje tijekom pretraživanja. Jedno preživjelo podudaranje uparenog hasha s ispravnim vremenskim poravnanjem neusporedivo je specifičnije od izoliranog vrha. Algoritam je strukturno dizajniran tako da zahtijeva samo mali dio ukupnih hasheva pjesme kako bi uspostavio neosporno podudaranje, što mu omogućuje besprijekorno prepoznavanje degradiranog zvuka.
Tehnički rječnik (Glosar)
| Pojam | Definicija |
|---|---|
| ADC | Analogno-digitalna pretvorba — transformira kontinuirani zvučni val u diskretne digitalne uzorke |
| Nyquistov teorem | Propisuje da se signal mora uzorkovati brzinom koja je barem dvostruko veća od njegove najviše frekvencije kako bi se mogao vjerno rekonstruirati |
| FFT | Brza Fourierova transformacija — algoritam složenosti za rastavljanje signala na frekvencijske komponente |
| STFT | Kratkotrajna Fourierova transformacija — primjenjuje FFT preko kliznih prozora kako bi se uhvatio frekvencijski sadržaj koji se mijenja s vremenom |
| Spektrogram | 2D prikaz audio signala kroz dimenzije vremena, frekvencije i amplitude |
| Hammingov prozor | Glatka funkcija sužavanja rubova koja se primjenjuje na svaki analitički okvir STFT-a radi smanjenja spektralnog curenja |
| Spektralni vrh | Lokalni maksimum u spektrogramu — točka čija amplituda premašuje sve susjedne točke u definiranom području |
| Konstelacijska mapa | Rijetki skup koordinata spektralnih vrhova koji čini osnovu za generiranje audio otiska |
| Kombinatorni hash | 32-bitni hash koji kodira vrijednosti — temeljna jedinica audio otiska |
| Poravnanje vremenskog pomaka | Tehnika sparivanja koja grupira pomake podudarnih hasheva radi potvrde koherentne identifikacije pjesme |
| Invarijantnost na translaciju | Svojstvo koje osigurava da je audio otisak neovisan o tome na kojem mjestu u pjesmi uzorak počinje |
“Bez strojnog učenja” — Bilješka za rušenje mitova u 2026. godini
Klasični algoritam Averyja Wanga pravo je remek-djelo čiste, determinističke 1D/2D obrade signala i brzog hashiranja. On ne sadrži neuronske mreže, nikakve težinske koeficijente niti modele obučene strojnim učenjem (machine learning).
Međutim, promatrajući arhitekturu iz perspektive 2026. godine, vrijedi dodati malu modernu fusnotu. Iako su temeljni okvir za sparivanje i indeksiranje audio otisaka i dalje usidreni u ovim točnim matematičkim principima, moderni Shazam (koji radi pod okriljem Appleova ekosustava) evoluirao je u hibridni sustav. Lagani, visoko optimizirani modeli dubokog učenja (Deep Learning) — specifično konvolucijske neuronske mreže (CNN) — danas se često primjenjuju u početnoj fazi prihvata signala. Ovi neuronski modeli služe kao ultra-učinkoviti filtri na samom ulazu kako bi eliminirali ekstremnu vanjsku buku kafića, izolirali vokale ili proveli odvajanje izvora zvuka prije nego što audio uopće uđe u fazu izrade konstelacijske mape.
Čak i uz te moderne dodatke umjetne inteligencije, glavninu posla, brzinu sparivanja i krajnju pouzdanost sustava i dalje u potpunosti nose prekrasni matematički temelji postavljeni prije više od dva desetljeća. Sljedeći put kada dodirnete taj gumb, svjedočit ćete kako Fourierova transformacija izvodi nešto uistinu bezvremensko.
